


BGP PIC Edge provides sub second convergence time in the case of edge link or node failure. BGP PIC is a useful for MPLS VPN service and can be provided by the Service provider as a value added service thus might provide additional revenue. BGP PIC provides sub second converge time in case link or node failure, and BGP PIC edge covers the edge failure cases.
Sub second convergence is not possible without PIC – Prefix Independent Convergence for BGP.
I am explaining this topic in deep detail in “BGP Zero to Hero” course.
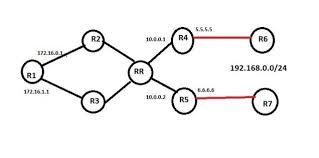
Figure -1 BGP PIC (Prefix Independent Convergence) Edge
In the above topology, R1 is the ingress PE, R4 and R5 are the ASBR nodes.Route Reflector is shown in the data path but it is not recommended in real network design.
Unfortunately backup next hop is not sent when BGP Route Reflector is introduced since RR selects and advertise only the best path for the given prefix.
For example, in the above topology, R6 and R7 both sends, 192.168.0.0/24 network but R1 can learn from the RR only one exit point (BGP next-hop), either R4 or R5.
There are many ways to send more than one best path from BGP RR but let’s not talk about them in this article, instead let’s assume, R1 learns the 192.168.0.0/24 prefix from R4 and R5.
How BGP PIC Edge Works ?
Let’s assume link between R1 learns the 192.168.0.0/24 prefix from R4 and R5 and choose the best exit point as R4. In this case R5 is marked as backup/alternate next hop and programmed into the FIB (Forwarding Information Base) of R1.
Let’s examine some failure and see how BGP PIC takes an action. – BGP PIC edge in case of edge link fails but ASBR doesn’t set next-hop self-
In case R4-46 link fails and R4 doesn’t set next-hop to itself (No next-hop self). In that case, link between R4 and r6 is advertised to the IGP. When R4-R6 link fails, R1 learns the failure from the IGP. BGP Next-hop tracking feature helps here.
IGP protocols register to the BGP Next-hop tracking process (Similar to IGP to BFD registration right ? )
When R1 learns the link failure between R4-R6, it immediately changes the BGP next hop for the 192.168.0.0/24 prefix to the R5. This switchover is done in less than a second regardless of the number of prefixes. Which mean even though you have million of BGP prefixes which need to be updated, still sub second convergence. (In this example for the simplicity only 192.168.0.0/24 prefix) – BGP PIC edge in case of edge link fails and ASBR set’s next-hop self –
When R4 sets BGP next hop to it self (It is done by setting the loopback as next-hop), since the loopback interface won’t go down, even though R1 learns the link failure (if the R4-R6 link is redistributed into IGP) from IGP, it doesn’t trigger BGP next-hop tracking to fails the BGP next hop , because BGP next hop for the 192.168.0.0/24 prefix is not the R4-R6 link address but the R4 loopback.
In this case R1 continue to send the traffic for the 192.168.0.0/24 prefix to the R4. But since the link between R4-R6 fails, when R4 receives the traffic destined to 192.168.0.0/24, it should send towards R5 immediately. (That’s why in the beginning I said, not only Ingress nodes, but also ASBRs should learn the alternate next-hop)
When do you set next-hop self on the edge BGP node ?
In MPLS VPN environment it is the best practice and almost mandatory to set the BGP next hop to the PE loopback. With that, transport LSP can be created to that PE loopback.
So far in the examples, BGP PIC edge protected the link failures.
– BGP PIC edge in case of edge node failure –
What if R4 fails ? How R1 would reach to that failure ?
In case R4 fails, IGP will trigger the BGP Next-hop tracking and R1 can change the next-hop as R5 for all the BGP prefixes. Convergence is again sub-second regardless of a number of BGP prefixes.
BGP PIC Edge Conclusion :
- BGP PIC – Prefix Independent Convergence is a BGP data plane convergence mechanism , not a control plane. Thus convergence time is only related with IGP convergence and prefix independent. If you have 500K full internet routing table, all of them will be installed in the FIB before the failure as a backup route and when the failure happens, next BGP next hop is used immediately.
- BGP PIC is also known as BGP Fast Reroute.
- BGP PIC is very suitable for MPLS VPN service, especially when the customer pay and ask tight convergence time in any failure.
- When BGP PIC is enabled, adding backup path for the million pf prefixes require additional memory and CPU, thats why resources should be monitored carefully
- BGP PIC is not necessarily only a BGP feature though. Since BGP can take advantage of recursion, hierarchical data plane arrangement. It is also not a Cisco proprietary protocol, most of the vendors implement BGP PIC today, Juniper is implementing BGP PIC as well, you can read it from here.
- In an IP environment without tunneling (GRE, L2tpv3,IPinIP) or encapsulation (MPLS) intermediate nodes which are not converged yet would send the packet back to R4 since they would think that R4 is still reachable so it would be temporary loop. In the case of MPLS or other tunneling mechanisms intermediate nodes wouldn’t need BGP so they would just send packet to second best path as per the R4 request.